
Table of contents

.svg)
.svg)
%20(31).png)
.png)
.png)
As seen in the chart below, the context size of Large Language Models (LLMs) are growing and currently range between 4,000 to 100,000 tokens. Hence there is the temptation to over simplify LLM enterprise implementations and directly and natively leverage the large context window of LLMs.

This avenue is very attractive in the short-term, in terms of favourable time-to-market, cost, solution complexity.
The disadvantages include the fact that the LLM becomes a black-box with no operational insights past the LLM input and output point.
Model performance substantially decreases as input contexts grow longer. — Source
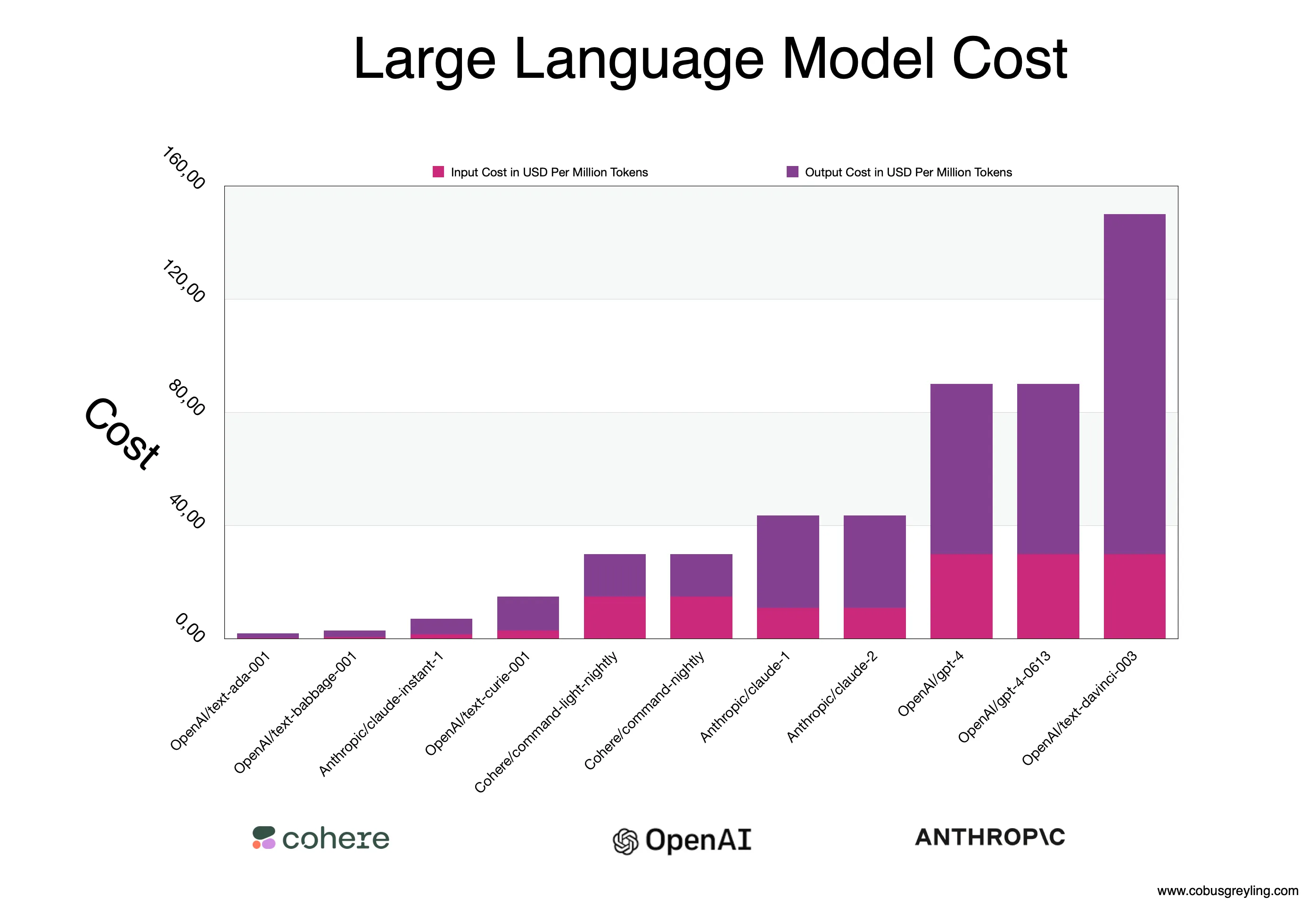
Considering the graph below, cost is also important in terms of token use during text input and output. It is clear from the token use/cost breakdown that the output token use can be exorbitant.

Hence there are cost considerations to truncate the text input and shortening the LLM output. This goes to illustrate that this truncating will necessitate the introduction of complexity if implementers do not want to be completely at the mercy and behest of LLM suppliers.
Added to these considerations, long context accuracy has come under the scrutiny.
A recent study has found that LLM performance is best when the relevant information is present at the start or end of the input context.
And in contrast, performance degrades when data relevant to the user query is in the middle of long context.

The graph below graphically illustrates how the accuracy improves at the beginning and end of the information entered.
And the performance deprecation when referencing data in the middle is also visible.

Added to this, models with extended context windows does not generally perform better than other smaller context models.

The graphs above shows different scenarios in terms of number of documents contrasted against accuracy and the position of the document holding the answer. Again performance is generally highest when relevant information is positioned at the very start or very end of the context, and rapidly degrades when models must reason over information in the middle of their input context.
I’m currently the Chief Evangelist @ HumanFirst. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.

.png)
.png)
.png)
.png)
.png)
